 Photo By freepik
Photo By freepik
“หากวันหนึ่งข้อมูลดิจิทัลที่เราคิดว่าคงอยู่ตลอดไปสูญหายไปทั้งหมด”
ในโลกของเรานั้น ทุกสิ่งล้วนถูกสร้างขึ้นมาเพื่อแก้ปัญหา ปัญหาของอะไรบางสิ่งบางอย่างเราจึง คิด วิธีการที่จะแก้ปัญหาเพื่อมุ่งไปข้างหน้าสู่อนาคตโดย สร้าง เส้นทางในการก้าวไปข้างหน้า และต่อให้คิดและสร้างแล้ว ก็อาจไม่ประสบความสำเร็จหากพวกเรายังไม่ได้ “ออกแบบ” เส้นทางดังกล่าวนั้นอย่างถูกต้อง ซึ่งการออกแบบในที่นี้ไม่ใช่แค่การออกแบบในเชิงรูปธรรม หรือออกแบบผลิตภัณฑ์เท่านั้น แต่หมายถึงการออกแบบในเชิงโครงสร้าง ออกแบบวิธีคิด และวิธีการทำงาน ด้วยเหตุนี้ต่อให้เจอปัญหาก็สามารถใช้กระบวนการคิดและออกแบบวิธีแก้ปัญหาได้อย่างสร้างสรรค์
ลองจินตนาการดูว่า ถ้าวันหนึ่งคุณอยากกลับไปดูภาพถ่ายจากทริปในปี 2010 หรือค้นหาข้อมูลวิทยานิพนธ์ที่เคยเจอบนเว็บไซต์หนึ่งเมื่อสิบปีก่อน แล้วพบว่ามัน “หายไป” ทุกอย่างที่เราคิดว่าโลกออนไลน์จะเก็บไว้ให้ตลอดไป กลับเลือนหายไปราวกับฝันที่ตื่นขึ้น คุณจะทำอย่างไร?
——————————————
ดิจิทัลที่ (ไม่) คงอยู่ตลอดไป
เอเธน่า ชาเปคิส-ซามูเอล เบสต์วาเตอร์-เอ็มม่า เรมี่ และ กอนซาโล ริเวโร – Pew Research Center
ในยุคดิจิทัลที่ดูเหมือนข้อมูลทุกอย่างจะถูกเก็บไว้อย่างไม่มีที่สิ้นสุด ความจริงกลับไม่สวยงามอย่างที่คิด “ความเสื่อมถอยทางดิจิทัล” (Digital Decay) กำลังเผยตัวให้เราเห็นชัดเจนขึ้น จากงานวิจัยของ Pew Research Center พบว่า 38% ของหน้าเว็บในปี 2013 หายไปในอีก 10 ปีต่อมา และในเดือนตุลาคม 2023 เพียงเดือนเดียว 1 ใน 4 ของหน้าเว็บที่เคยมีอยู่ระหว่างปี 2013-2023 ไม่สามารถเข้าถึงได้อีกต่อไป
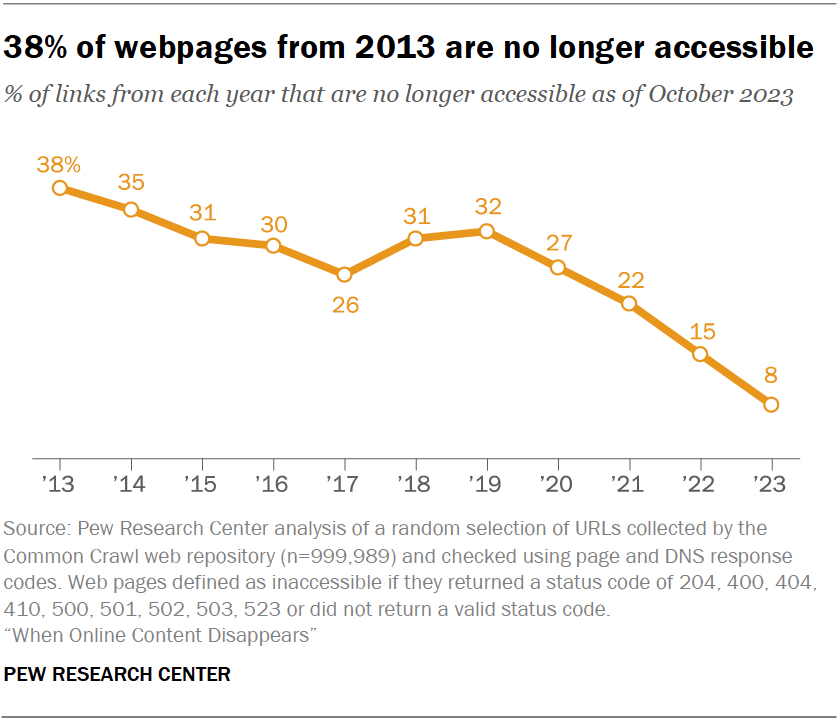 Photo by PEW Research Center
Photo by PEW Research Center
ลิงก์เสียที่พาเราสูญเสียโลกเก่า
คิดดูว่าเราใช้ชีวิตออนไลน์มากแค่ไหน ทั้งการหาข่าวสารบนเว็บไซต์รัฐบาล อ่านบทความบน Wikipedia หรือเลื่อนฟีดโซเชียลมีเดีย แต่กลับพบว่าข้อมูลเหล่านี้ไม่ได้ยั่งยืนอย่างที่คิด!
- 23% ของหน้าเว็บข่าวมี ลิงก์เสีย อย่างน้อยหนึ่งลิงก์
- 54% ของหน้า Wikipedia มีลิงก์ในส่วน “อ้างอิง” ที่ชี้ไปยังหน้าเว็บที่ไม่มีอยู่อีกต่อไป
- ทวีตบนแพลตฟอร์ม X (Twitter เดิม) เกือบ 1 ใน 5 หายไปจากการมองเห็นในเวลาเพียงไม่กี่เดือน
ในบางกรณี เจ้าของบัญชีลบโพสต์ทิ้งหรือปิดบัญชีไป แต่ในกรณีอื่นๆ เว็บไซต์ที่เคยเป็น “เจ้าบ้าน” ก็ล่มหรือถูกลบออกไปทั้งหมด อินเทอร์เน็ตเป็นแหล่งรวมข้อมูลชีวิตสมัยใหม่ที่กว้างใหญ่ไพศาลอย่างที่เราไม่อาจจินตนาการได้ โดยมีหน้าเว็บที่ถูกจัดทำดัชนีไว้กว่าแสนล้านหน้า แม้ว่าผู้ใช้ทั่วโลกจะพึ่งพาอินเทอร์เน็ตเพื่อเข้าถึงหนังสือ รูปภาพ บทความข่าว และทรัพยากรอื่นๆ แต่บางครั้งเนื้อหาเหล่านี้ก็หายไปจากสายตาการวิเคราะห์ใหม่ของศูนย์วิจัย Pew แสดงให้เห็นว่าเนื้อหาออนไลน์นั้นผ่านไปอย่างรวดเร็วเพียงใด
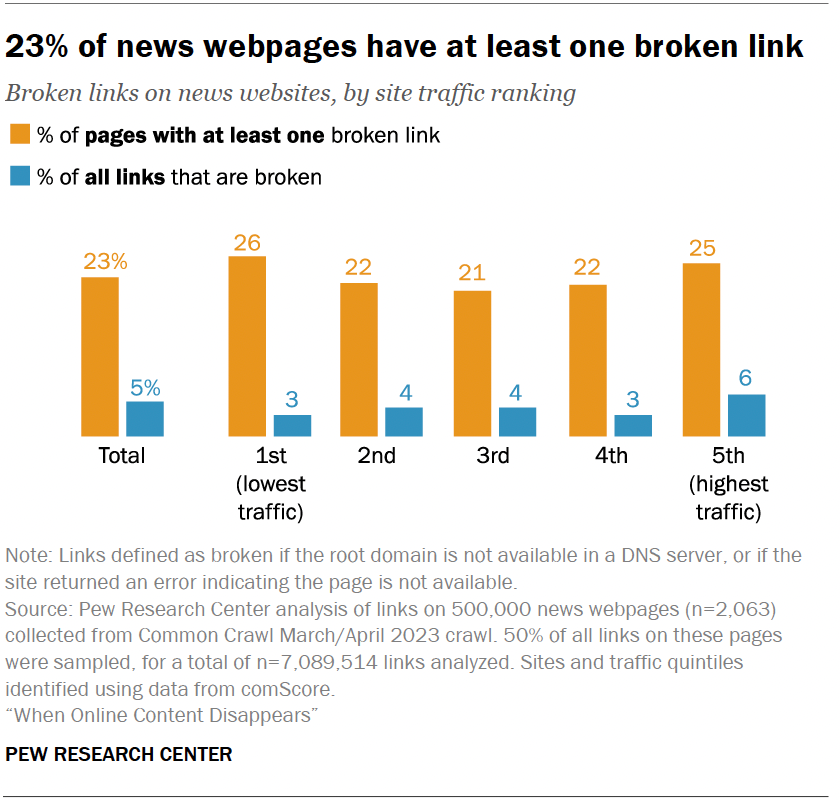
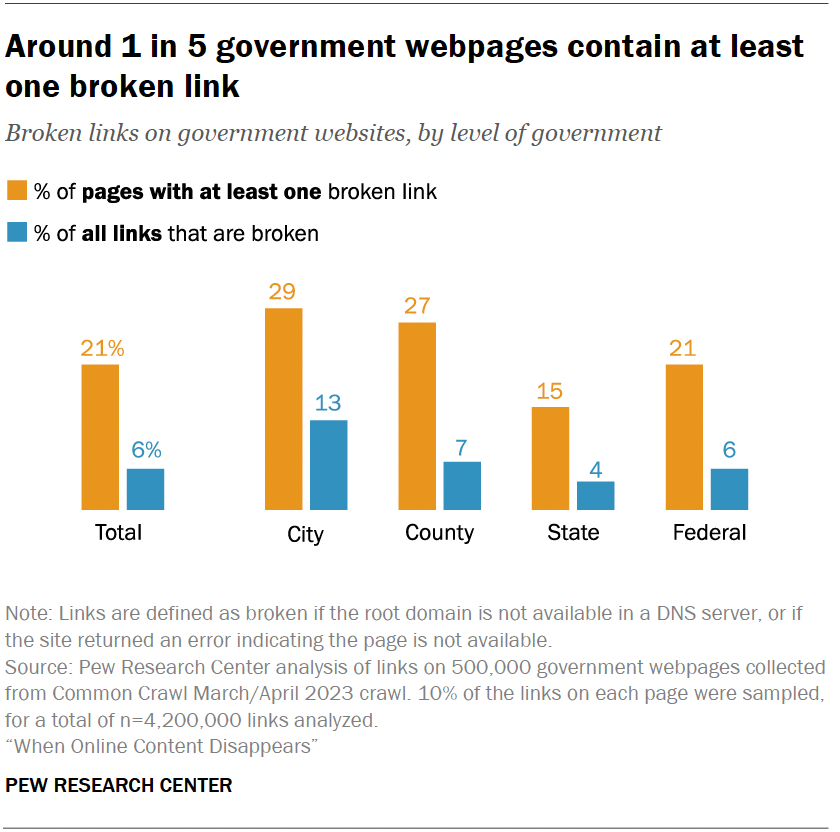
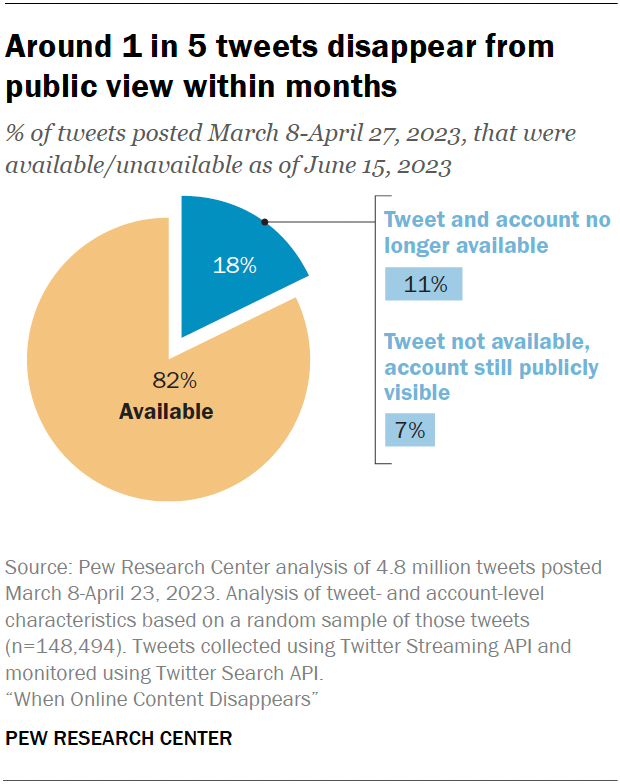 Photo by PEW Research Center
Photo by PEW Research Center
เพื่อดูว่าการเสื่อมถอยของดิจิทัลส่งผลต่อโซเชียลมีเดียอย่างไร เราได้รวบรวมตัวอย่างทวีตแบบเรียลไทม์บนแพลตฟอร์มโซเชียลมีเดีย X (เดิมเรียกว่า Twitter) ในช่วงฤดูใบไม้ผลิปี 2023 และติดตามทวีตเหล่านั้นเป็นเวลาสามเดือน เราพบว่า Photo by PEW Research Center
Photo by PEW Research Center
- ทวีตเกือบ 1 ใน 5 จะไม่ปรากฏต่อสาธารณะบนเว็บไซต์อีกต่อไปหลังจากโพสต์เพียงไม่กี่เดือน ใน 60% ของกรณีเหล่านี้ บัญชีที่โพสต์ทวีตในตอนแรกจะถูกตั้งค่าเป็นส่วนตัว ระงับ หรือลบทิ้งทั้งหมด ในอีก 40% เจ้าของบัญชีได้ลบทวีตแต่ละรายการ แต่บัญชีนั้นยังคงอยู่
- ทวีตบางประเภทมีแนวโน้มที่จะหายไปมากกว่าประเภทอื่น ทวีตมากกว่า 40% ที่เขียนเป็นภาษาตุรกีหรืออาหรับจะไม่ปรากฏบนเว็บไซต์อีกต่อไป ภายในสามเดือนหลังจากโพสต์ และทวีตจากบัญชีที่มีการตั้งค่าโปรไฟล์เริ่มต้นมีแนวโน้มที่จะหายไปจากมุมมองสาธารณะ
——————————————
เรากำลังสูญเสียประวัติศาสตร์ดิจิทัลของเรา แล้วInternet Archives สามารถช่วยได้หรือไม่?
คริส สโตเกล-วอล์คเกอร์ – นักข่าวสายเทคโนโลยีและอาจารย์ในอังกฤษ
งานวิจัยแสดงให้เห็นว่า 25% ของหน้าเว็บที่โพสต์ระหว่างปี 2013 ถึง 2023 ได้หายไปแล้ว และมีองค์กรไม่กี่แห่งที่พยายามรักษาข้อมูลเว็บไว้ แต่มีความเสี่ยงใหม่ ๆ ที่กำลังคุกคามอินเตอร์เน็ต
เราสามารถเรียนรู้ว่า ชาวปอมเปอีรับประทานอาหารเช้าอย่างไรเมื่อ 2,000 ปีก่อน จากเศษกระดาษปาปิรุส ภาพโมเสก และแผ่นขี้ผึ้งที่หลงเหลืออยู่ หรือเราเรียนรู้ว่าในศตวรรษที่ 11 มีการเลี้ยงปศุสัตว์กี่ตัวในฟาร์มที่นอร์ธัมเบอร์แลนด์ จากหนังสือ Domesday ซึ่งเป็นเอกสารที่เก่าแก่ที่สุดในหอจดหมายเหตุแห่งชาติของสหราชอาณาจักร เราสามารถมองเห็นชีวิตสังคมของยุควิคตอเรียผ่านจดหมายและนวนิยาย
ในอนาคต นักประวัติศาสตร์อาจประสบความยากลำบากในการเข้าใจชีวิตในต้นศตวรรษที่ 21 อย่างถ่องแท้ เนื่องจากวิถีชีวิตในยุคดิจิทัล และความพยายามในการเก็บข้อมูลของโลก ที่ผลิตขึ้นในยุคนี้มีน้อยมาก
อย่างไรก็ตาม มีกลุ่มองค์กรที่ไม่เป็นทางการกำลังต่อสู้กับความสูญเสียทางดิจิทัลนี้อยู่ องค์กรที่มีชื่อเสียงที่สุดในเรื่องนี้ก็คือ Internet Archive องค์กรไม่แสวงหาผลกำไรในสหรัฐฯ ที่ก่อตั้งในปี 1996 โดยบรูว์สเตอร์ คาห์ล ผู้บุกเบิกอินเทอร์เน็ต องค์กรนี้ได้เริ่มโครงการเก็บข้อมูลที่อาจเรียกได้ว่ายิ่งใหญ่ที่สุดในประวัติศาสตร์ โดยรวบรวมหน้าเว็บ 866 พันล้านหน้า หนังสือ 44 ล้านเล่ม วิดีโอภาพยนตร์และรายการโทรทัศน์ 10.6 ล้านวิดีโอ และอีกมากมาย ข้อมูลเหล่านี้ถูกเก็บไว้ที่ศูนย์ข้อมูลหลายๆ แห่งทั่วโลก เพื่อป้องกันการสูญเสียข้อมูลทางดิจิทัล
แต่ความเสี่ยงมีมากมาย ไม่ใช่แค่เทคโนโลยีเท่านั้นที่อาจจะล้มเหลว แต่ผลกระทบที่อาจเกิดขึ้นหากเราสูญเสียข้อมูลทางดิจิทัลไปนั้นก็คือ
- สถาบันต่างๆ อาจล้มเหลวทางข้อมูล
- บริษัทต่างๆ อาจต้องเลิกกิจการ
- องค์กรข่าวต่างๆ จะถูกองค์กรข่าวอื่นๆ เข้าครอบงำธุรกิจ (Take Over Information)
- หรือในท้ายที่สุดอาจต้องปิดตัวลง
มาร์ก เกรแฮม ผู้อำนวยการ Wayback Machine ของ Internet Archive ซึ่งเป็นเครื่องมือที่รวบรวมและจัดเก็บสแน็ปช็อตของเว็บไซต์ต่างๆ กล่าวว่า “มีแรงจูงใจมากมายในการนำเนื้อหาไปเผยแพร่ทางออนไลน์ แต่องค์กรต่างๆ แทบไม่ได้ผลักดันให้รักษาเนื้อหาเหล่านี้ไว้ในระยะยาวด้วยซ้ำ”
แม้ว่า Internet Archive จะประสบความสำเร็จมาจนถึงทุกวันนี้ แต่หน่วยงานและหน่วยงานอื่นๆ ที่คล้ายกันก็ต้องเผชิญกับภัยคุกคามทางการเงิน ความท้าทายทางเทคนิค การโจมตีทางไซเบอร์ และการต่อสู้ทางกฎหมายจากธุรกิจที่ไม่เห็นด้วยกับแนวคิดการคัดลอกทรัพย์สินทางปัญญาของตนให้เข้าถึงได้ฟรี และจากความพ่ายแพ้ในศาลเมื่อไม่นานนี้ แสดงให้เห็นว่าโครงการช่วยเหลือนี้อาจดำเนินไปได้เพียงชั่วครั้งชั่วคราว เช่นเดียวกับเนื้อหาที่หน่วยงานพยายามปกป้อง
“องค์ความรู้ ความบันเทิง ข่าวสาร และบทสนทนาของเรา มีอยู่เฉพาะในสภาพแวดล้อมดิจิทัลเท่านั้น” เกรแฮมกล่าว “สภาพแวดล้อมนั้นเปราะบางอย่างแท้จริง”
 Photo By Freepik
Photo By Freepik
——————————————
บันทึกประวัติศาสตร์ของเรา
หน้าเว็บ 1ใน4 ที่มีอยู่ในช่วงเวลาใดช่วงเวลาหนึ่งระหว่างปี 2013 ถึง 2023 ในปัจจุบันนั้น ไม่ได้เป็นแบบเดิมอีกต่อไป ซึ่งเป็นไปตามการศึกษาวิจัยล่าสุดของ Pew Research Center นักวิจัยพบว่าปัญหารุนแรงขึ้นเมื่อหน้าเว็บเก่าลง โดย 38% ของหน้าเว็บที่ Pew พยายามเข้าถึงซึ่งมีอยู่ในปี 2013 ไม่สามารถใช้งานได้อีกต่อไป แต่ยังสงผลกระทบกับสิ่งพิมพ์ที่ตีพิมพ์ล่าสุดอีกด้วย โดยหน้าเว็บประมาณ 8% ที่เผยแพร่ในช่วงเวลาใดช่วงเวลาหนึ่งระหว่างปี 2023 นั้นหายไปภายในเดือนตุลาคมของปีนั้น หมายความว่า ข้อมูลอ้างอิงของสื่อสิ่งพิมพ์ได้หายไปจากอินเตอร์เน็ต
นี่ไม่ใช่แค่ความกังวลของนักประวัติศาสตร์เท่านั้น จากการศึกษาพบว่าเว็บไซต์ของรัฐบาล 1 ใน 5 แห่งมีลิงก์เสียอย่างน้อย 1 ลิงก์ และ Pew ยังพบว่าบทความ Wikipedia มากกว่าครึ่งหนึ่งมีลิงก์เสียในส่วนของการอ้างอิง ซึ่งหมายความว่า หลักฐานที่สนับสนุนข้อมูลในสารานุกรมออนไลน์กำลังเสื่อมสลายลงเรื่อยๆ
แต่ต้องขอบคุณงานของ Internet Archive ที่ทำให้ลิงก์เสียเหล่านั้นสามารถเข้าถึงได้ และเป็นเวลาหลายทศวรรษที่โครงการ Wayback Machine ของ Internet Archive ได้ส่ง A.I. ไปสำรวจอินเทอร์เน็ตที่สลับซับซ้อน A.I. เหล่านี้จะดาวน์โหลดสำเนาส่วนที่ใช้งานได้ของเว็บไซต์ที่มีการเปลี่ยนแปลงตามช่วงเวลา โดยจะบันทึกหน้าเดียวกันหลายครั้งในวันเดียว และเปิดให้สาธารณชนเข้าถึงได้ฟรี
“เมื่อเราลองเข้าไปดูว่ามี URL เหล่านี้กี่รายการใน Wayback Machine เราก็พบว่ามี URL เหล่านี้ถึงสองในสามรายการที่มีการเปลี่ยนแปลง” เขากล่าว Internet Archive กำลังดำเนินการตามเป้าหมาย นั่นก็คือ การบันทึกข้อมูลของสังคมออนไลน์ไว้เพื่อคนรุ่นหลัง
นักประวัติศาสตร์ในอนาคตอาจต้องดิ้นรนเพื่อทำความเข้าใจอย่างถ่องแท้ว่าเราใช้ชีวิตอย่างไรในช่วงต้นศตวรรษที่ 21
องค์กรอื่นๆ อีกหลายแห่ง ทั้งขนาดใหญ่และเล็กต่างก็ทำแบบเดียวกัน ตัวอย่างเช่น หอสมุดรัฐสภาสหรัฐฯ ได้เก็บรักษาเว็บไซต์ของรัฐบาล เว็บไซต์ของสมาชิกรัฐสภา และคอลเลกชันเว็บไซต์ข่าวของสหรัฐฯ หอสมุดรัฐสภาเก็บรักษาสำเนา ทวีตทุกฉบับ ที่ส่งมาตั้งแต่ก่อตั้ง Twitter จนกระทั่งโครงการถูกปิดตัวลงในปี 2017 ในฝั่งยุโรป UK Web Archive ก็ดำเนินการรวบรวมเว็บไซต์ที่มีชื่อโดเมน .UK เป็นประจำทุกปี โดยบันทึกภาพรวมอินเทอร์เน็ตของอังกฤษอย่างน้อยปีละครั้ง และในปี 2022 ได้มีกลุ่มอาสาสมัครออกเดินทางไปเพื่อช่วยเหลืออินเทอร์เน็ตของยูเครนที่ได้รับผลกระทบจากการโจมตีทางไซเบอร์ จากรัสเซีย แต่ขอบเขตของโครงการเหล่านี้ค่อนข้างแคบเมื่อเทียบกับ Internet Archive ที่มุ่งหวังที่จะบันทึกครอบคลุมในทุกๆ ด้านของโลกอินเตอร์เน็ต เมื่อพิจารณาจากทรัพยากรที่มีอยู่แล้วเป็นไปไม่ได้เลยที่จะรวบรวมสิ่งต่างๆ ในอินเทอร์เน็ตทั้งหมด แต่ระบบของ Internet Archive นั้นมีเครือข่ายที่กว้างมาก คอลเล็กชันของ Internet Archive นั้นครอบคลุมมากจนบางครั้งอาจรู้สึกเหมือนเป็นบันทึกของเว็บที่ใช้งานได้ครบถ้วนทุกฟังก์ชั่นเลยทีเดียว
 Photo by Freepik
Photo by Freepik
——————————————
ความสำเร็จนำมาซึ่งความประมาท
เอกสารที่สามารถเข้าถึงได้โดยสาธารณะของ Archive ช่วยรักษาบันทึกของชีวิตเราในยุคปัจจุบัน การอ้างอิงสำเนาเว็บไซต์จาก Wayback Machine ของ Internet Archive กลายมาเป็นแนวทางปฏิบัติมาตรฐานบน Wikipedia แทนที่จะอ้างอิงเว็บไซต์ต้นฉบับเอง นอกจากนี้ องค์กรยังเก็บรักษาคอลเล็กชั่นสื่อจำนวนมากที่มีมาก่อนยุคดิจิทัลอีกด้วย ซีรีส์ตลกยอดนิยมปี 1977 เรื่องFernwood 2 Night ไม่สามารถรับชมได้บนบริการสตรีมมิ่งใดๆ แต่คุณสามารถรับชมได้ฟรีบน Internet Archive หนังสือ นิตยสาร และเว็บไซต์ต่างๆอ้างอิงสำเนาดิจิทัลที่สแกนจาก Internet Archive ของหนังสือที่ไม่มีให้บริการในห้องสมุดจริง นอกจากนี้ Internet Archive ยังทำหน้าที่เป็นเครื่องมือรักษาข้อมูลสำหรับสาธารณะอีกด้วย ใครๆ ก็สามารถอัปโหลดวิดีโอ เว็บไซต์ และสิ่งอื่นๆ แทบทุกอย่างไปยังเซิร์ฟเวอร์ขององค์กรได้
“ทุกๆ สองสามปีจะมีแพลตฟอร์มใหม่เกิดขึ้นและจู่ๆ แรงผลักดันทางเศรษฐกิจก็พังทลายลง” – แอนดรูว์ แจ็กสัน
คอลเลกชันหลักๆ ที่ Wayback Machine กู้มาจากกองขยะดิจิทัล ได้แก่บันทึกเว็บไซต์ที่สร้างขึ้นบน GeoCitiesซึ่งเป็นบริการเว็บโฮสติ้งส่วนบุคคลที่เลิกใช้งานไปแล้ว นานก่อนโซเชียลมีเดีย GeoCities เป็นหนึ่งในแพลตฟอร์มแรกๆ ที่ทำให้ใครๆ ก็สร้างเว็บไซต์ของตัวเองได้อย่างง่ายดายนักประวัติศาสตร์มองว่า GeoCities เป็นหนึ่งในบทที่สำคัญที่สุดในยุคแรกของอินเทอร์เน็ตทั่วโลก หากไม่ได้รับความพยายามจาก Internet Archive เว็บไซต์ส่วนใหญ่คงสูญหายไป ในประวัติศาสตร์ล่าสุด คณะกรรมการรัฐสภาสหรัฐฯพึ่งพา Internet Archiveในการเก็บรักษาบทความและเอกสารที่เกี่ยวข้องกับการจลาจลในวันที่ 6 มกราคม
 Photo By Bettmann
Photo By Bettmann
——————————————
เสียงที่หายไปของยุคดิจิทัล
Andrew Jackson สถาปนิกด้านเทคนิคของทะเบียนการอนุรักษ์จาก Digital Preservation Coalition ซึ่งเป็นกลุ่มรณรงค์และองค์กรการกุศลที่ให้คำแนะนำเกี่ยวกับวิธีการรักษาไฟล์ดิจิทัลออนไลน์ของโลก กล่าวว่า “ทุกๆ สองสามปี จะมีแพลตฟอร์มใหม่ๆ เกิดขึ้น และจู่ๆ แรงผลักดันทางเศรษฐกิจก็พังทลายลง” “นั่นคือแหล่งใหญ่ของการเปลี่ยนแปลง”
เว็บไซต์ข่าวเทคโนโลยี CNET เผชิญกับกระแสตอบรับเชิงลบในปี 2023 หลังจากมีรายงานว่าบริษัทได้ลบบทความหลายหมื่นบทความซึ่งนับเป็นการสูญเสียประวัติไปหลายสิบปี การตอบสนองของ CNET อย่างหนึ่งก็คือคำมั่นสัญญาว่าบทความที่ถูกลบทั้งหมดจะได้รับการเก็บรักษาไว้ใน Wayback Machine นักวิจารณ์หลายคนโต้แย้งว่าบริษัทถือว่า Internet Archive เป็นเรื่องปกติ โดยละเลยความรับผิดชอบในการจัดเก็บเอกสารของตนเอง
ตามข้อมูลของศูนย์วิจัย Pew หน้าเว็บทั้งหมด 1 ใน 4 ที่เคยมีอยู่ในช่วงระหว่างปี 2013 ถึง 2023 ในปัจจุบัน…
“แม้ว่า Google และเครื่องมือค้นหาอื่นๆ จะกระตุ้นให้คุณรักษา URL ให้เสถียร แต่ในทางเทคนิคแล้ว การทำเช่นนั้นค่อนข้างยาก” แจ็คสันกล่าว “ทุกครั้งที่บริษัทใหม่ทำการปรับปรุงเว็บไซต์ บริษัทจะต้องคำนวณว่าจะพยายามรักษา URL ใหม่ไว้ได้มากเพียงใด”
แต่สิ่งที่ควรค่าแก่การจดจำคือ Internet Archive คือองค์กรไม่แสวงหากำไรที่ได้รับเงินสนับสนุนจากการบริจาคของมูลนิธิการกุศล องค์กรนี้ดำเนินโครงการที่ไม่มีวันสิ้นสุดและมีค่าใช้จ่ายเพิ่มขึ้นอย่างทวีคูณ Internet Archive เสนอตัวเป็นห้องสมุดชั้นนำของโลกสำหรับชีวิตดิจิทัลของเรา ในขณะที่เว็บเข้าสู่ทศวรรษที่สี่ โปรเจ็กต์ที่ไม่เป็นทางการนี้ได้กลายเป็นเสาหลักที่สำคัญของอินเทอร์เน็ต
แต่ในขณะที่การพึ่งพา Internet Archive ของเราเติบโตขึ้น ภัยคุกคามก็เพิ่มมากขึ้นตามไปด้วย
 Photo by Grigorii Shcheglov on Unsplash
Photo by Grigorii Shcheglov on Unsplash
——————————————
จุดล้มเหลวเพียงจุดเดียว
เมื่อสัปดาห์ที่แล้ว องค์กรได้ประกาศความร่วมมือครั้งสำคัญกับ Googleโดยยักษ์ใหญ่ด้านเทคโนโลยีแห่งนี้จะรวมลิงก์ไปยัง Wayback Machine ไว้ในผลการค้นหา แม้ว่าจะไม่มีการเปิดเผยรายละเอียดทางการเงินเกี่ยวกับข้อตกลงดังกล่าวก็ตาม
ข่าวล่าสุดอื่นๆ แสดงให้เห็นว่าโครงการดังกล่าวยังคงเปราะบาง ช่องโหว่ดังกล่าวถูกเปิดเผยในคดีความที่ฟ้อง Internet Archive โดยสำนักพิมพ์หนังสือขนาดใหญ่ 4 แห่ง ซึ่งกล่าวหาว่าแนวทางปฏิบัติของ Internet Archive ในการสแกนหนังสือจริงและให้ยืมสำเนาดิจิทัลนั้นละเมิดกฎหมายลิขสิทธิ์ของสหรัฐอเมริกา ก่อนเกิดโรคระบาด Internet Archive จะยืมสำเนาดิจิทัลได้ครั้งละ 1 สำเนาสำหรับหนังสือจริงแต่ละเล่มในคอลเล็กชันเท่านั้น แต่ระหว่างการปิดตัวลงเนื่องจากโควิด องค์กรได้ยกเลิกข้อจำกัดดังกล่าว โดยอนุญาตให้ผู้ใช้ยืมสำเนาดิจิทัลของหนังสือได้ไม่จำกัดจำนวนเพื่อชดเชยการปิดห้องสมุดจริง
ศาลสหรัฐฯตัดสินว่าการกระทำดังกล่าวถือเป็นสิ่งผิดกฎหมายในปี 2023 และในช่วงต้นเดือนกันยายน คำอุทธรณ์ของ Internet Archive ต่อคำตัดสินดังกล่าวถูกปฏิเสธก่อนหน้านี้ องค์กรดังกล่าวเคยกล่าวไว้ว่าตกลงที่จะจ่ายเงินจำนวนหนึ่งให้กับกลุ่มการค้าในอุตสาหกรรมสิ่งพิมพ์ในคดีนี้โดยไม่เปิดเผย
หลังจากคดีความดังกล่าวจบลง Internet Archive กำลังต่อสู้คดีในศาลอีกครั้งกับค่ายเพลงที่ฟ้องร้องบริษัทเพลงในข้อหาแปลงแผ่นเสียงเป็นดิจิทัล ซึ่งหากแพ้คดี บริษัทอาจต้องสูญเสียเงิน 400 ล้านเหรียญสหรัฐ (ประมาณ 305 ล้านปอนด์) จำนวนเงินดังกล่าวอาจส่งผลกระทบต่อการอยู่รอดขององค์กรไม่แสวงหากำไรแห่งนี้
คอลเลกชันของ Internet Archive ที่มีมายาวนานกว่าสามทศวรรษครอบคลุมหน้าเว็บกว่าแสนล้านหน้า (เครดิต: Serenity Strull/ Getty Images)
คริส ฟรีแลนด์ ผู้อำนวยการฝ่ายบริการห้องสมุดของ Internet Archive กล่าวว่าทางองค์กรกำลังพิจารณา คำชี้แจงของศาลเกี่ยวกับคำตัดสินดังกล่าว
การต่อสู้ทางกฎหมายเกี่ยวกับการดำรงอยู่ไม่ใช่ภัยคุกคามเพียงอย่างเดียวที่คุกคามโลกของการเก็บรักษาข้อมูลดิจิทัล UK Web Archive ของหอสมุดแห่งชาติอังกฤษต้องเผชิญกับความท้าทายทางเทคนิคอันเลวร้ายเมื่อ เดือนตุลาคม 2023 ที่ถูกโจมตี ทางไซเบอร์จนทำให้ระบบดิจิทัลของหอสมุดต้องปิดตัวลง เกือบหนึ่งปีต่อมา UK Web Archive ยังคงต้องรับมือกับผลกระทบดังกล่าว การเข้าถึงคอลเล็กชันส่วนใหญ่ทางออนไลน์ยังคงไม่พร้อมใช้งาน
ในเดือนพฤษภาคม 2024 Internet Archive ได้ประกาศว่ากำลังเผชิญกับการโจมตีแบบ Distributed Denial of Service (DDoS) ครั้งใหญ่ ในการโจมตีแบบ DDoS ผู้ก่อกวนหรือผู้กระทำผิดอื่นๆ จะสร้างระบบอัตโนมัติเพื่อโจมตีเว็บไซต์ด้วยจำนวนผู้เยี่ยมชมจำนวนมาก โดยพยายามผลักเว็บไซต์ให้ออฟไลน์โดยทำให้เซิร์ฟเวอร์ของเว็บไซต์ล้นมือ ในช่วงพีค มีผู้เข้าชมพร้อมกันหลายหมื่นคนต่อวินาที บริการต่างๆ รวมถึง Wayback Machine ก็ล่มลง ส่งผลให้การทำงานปกติของการเก็บถาวรหยุดชะงักไปชั่วขณะ และอาจมีช่องว่างถาวรในบันทึกทางประวัติศาสตร์อันเป็นผลจากการโจมตีดังกล่าว
เรามีเอกสารมากมายจากอดีต แต่เรามีเอกสารและเสียงของบางคนเท่านั้น และเสียงที่หายไปเหล่านั้นมีความสำคัญอย่างยิ่ง และถูกลบทิ้งไปแล้ว – มาร์ ฮิกส์
แจ็คสันกล่าวว่า Internet Archive “ก่อตั้งโดยบุคคลเพียงคนเดียวและกลายมาเป็นแกนหลัก” “และยังดูเหมือนเป็นจุดล้มเหลวเพียงจุดเดียวที่อาจเกิดขึ้นได้ แม้ว่าจะซับซ้อนกว่าอาสาสมัครมาก แต่ก็เป็นสถาบันเดียวในภูมิภาคเดียว ภายใต้กรอบกฎหมายเดียว”
องค์กรต่างๆ ก็มีความกังวลเช่นเดียวกันนี้ หากการทำงานของ Internet Archive หยุดลงและ “ช่องว่างนั้นไม่ได้รับการเติมเต็มทันที สิ่งต่างๆ มากมายที่เผยแพร่อยู่บนเว็บสาธารณะในปัจจุบันก็จะตกอยู่ในความเสี่ยง” เกรแฮมกล่าว
เขาชัดเจนว่า Internet Archive จะไม่ละทิ้งความรับผิดชอบในเร็วๆ นี้ แต่โครงการนี้สามารถใช้ความช่วยเหลือจากภายนอกได้ “มีโอกาสให้คนอื่นๆ มากมายเข้ามามีส่วนสนับสนุนในหลากหลายวิธี” เขากล่าว
 Photo by Freepik
Photo by Freepik
——————————————
อนาคตที่เราต้องออกแบบร่วมกัน
เนื่องจากไม่มีความพยายามอย่างเป็นทางการในการจัดระเบียบความพยายามในการอนุรักษ์อินเทอร์เน็ต โครงการนี้จึงถูกทิ้งไว้ให้กับนักเล่นอดิเรก อาสาสมัคร และกลุ่มหน่วยงานที่ไม่เป็นทางการบางกลุ่มที่โดยทั่วไปทำงานอย่างอิสระ
Mar Hicks นักประวัติศาสตร์ด้านเทคโนโลยีแห่งมหาวิทยาลัยเวอร์จิเนียกล่าวว่า “การตอบสนองต่อการเก็บถาวรแบบกระจายอำนาจนั้นสมเหตุสมผล แต่ปัญหาประการหนึ่งก็คือลำดับความสำคัญที่แตกต่างกัน”
ฮิกส์ชี้ให้เห็นว่าสิ่งแรกๆ ที่บรรณารักษ์จะพิจารณาเมื่อสร้างคลังเอกสารคือสิ่งที่ควรให้ความสำคัญเป็นอันดับแรก “และเมื่อคลังเอกสารกระจายอำนาจมากขนาดนี้ ลำดับความสำคัญก็จะแตกต่างไปมาก” ฮิกส์กล่าว “จะมีผู้คนในกลุ่มที่ให้ความสำคัญกับการพยายามคว้าทุกสิ่งทุกอย่าง ซึ่งพวกเขาอาจให้ความสำคัญกับความสมบูรณ์มากที่สุดเท่าที่จะทำได้” จากนั้นจะมีผู้คนอีกกลุ่มหนึ่งที่มุ่งเน้นเฉพาะในบางพื้นที่ เช่น ความพยายามในการเก็บถาวรเอกสารในสหราชอาณาจักร
สิ่งที่น่ากังวลเกี่ยวกับแนวทางเฉพาะหน้าแบบกระจายอำนาจเช่นนี้ก็คือ อาจเกิดการทับซ้อนกันได้ ซึ่งหมายความว่าทรัพยากรการเก็บถาวรที่มีค่าจะสูญเปล่าไปกับการทำสำเนาซ้ำหรือสามชุดของเว็บไซต์ยอดนิยม ในขณะเดียวกัน บางพื้นที่ที่อาจมีความสำคัญทางประวัติศาสตร์กลับถูกมองข้ามไปเพราะตกอยู่ภายใต้ความรับผิดชอบของกลุ่มที่แตกต่างกัน
หนังสือเป็นทรัพยากรที่มีจำกัดอย่างเห็นได้ชัด อาจสูญหายหรือเสียหายได้ แต่อินเทอร์เน็ตให้ความรู้สึกเข้าถึงได้ง่าย ใครก็ตามที่มีการเชื่อมต่ออินเทอร์เน็ตสามารถเปิดเว็บเบราว์เซอร์และป้อน URL ได้ ทุกอย่างอยู่ที่นั่น – จนกว่าจะไม่อยู่
“บรรณารักษ์จะบอกคุณว่าปัญหาเหล่านี้มีมานานแล้ว” ฮิกส์กล่าว แต่ปัญหาเหล่านี้ยิ่งเลวร้ายลงไปอีกเนื่องจากปริมาณข้อมูลจำนวนมากที่ถูกผลิตขึ้นในโลกดิจิทัลของเรา มีการส่ง อีเมลเกือบพันล้านฉบับทุกวัน YouTube รายงานว่าเนื้อหาวิดีโอมากกว่า 500 ชั่วโมง ถูกโพสต์บนแพลตฟอร์มทุกนาที
ฮิกส์กล่าวว่าอินเทอร์เน็ตเป็น “ท่อส่งข้อมูลและสื่อต่างๆ” “การพยายามดักจับทุกสิ่งที่ออกมาจากท่อส่งข้อมูลนั้นไม่สมเหตุสมผลเลย เพราะนั่นจะไม่สมเหตุสมผลเมื่อพิจารณาจากทรัพยากร”
ในแง่หนึ่ง นี่เป็นปัญหาเก่าแล้ว “ในฐานะนักประวัติศาสตร์ เรามีปัญหาเดียวกันนี้” ฮิกส์กล่าว “เรามีเอกสารมากมายจากอดีต แต่เรามีเอกสารบางส่วนและเสียงของผู้คนบางกลุ่มเท่านั้น และเสียงจำนวนมากที่หายไปนั้นมีความสำคัญอย่างยิ่ง และถูกลบออกไปแล้ว”
สำหรับฮิกส์ จำเป็นต้องมีการให้ความสำคัญเป็นลำดับแรกเกี่ยวกับสิ่งที่จะได้รับการปกป้องจากรอยเท้าดิจิทัลของคนรุ่นเรา มิฉะนั้น เราจะเสี่ยงต่อการที่ต้นทุนที่พุ่งสูงขึ้นอย่างรวดเร็วจะทำให้ความพยายามในการปกป้องประวัติศาสตร์ของเว็บต้องหยุดชะงักลง ไม่ต้องพูดถึงไฟล์ดิจิทัลจำนวนมหาศาลที่ยังคงอยู่แบบออฟไลน์
“หากคุณต้องเก็บทุกอย่างไว้ มันจะกลายเป็นเรื่องแพงมาก” แจ็กสันจาก Digital Preservation Coalition กล่าว “มักจะมีเนื้อหาเก่าๆ หรือเนื้อหาที่ไม่น่าสนใจ [ซึ่ง] มักจะถูกละเลยไป” เขากล่าว
“เราไม่ได้จับภาพโลกที่ไม่ใช่ตะวันตกได้ดีนัก” แจ็กสันยอมรับ “ตอนนี้มีช่องว่างอยู่รอบๆ ความไม่สมบูรณ์ในโดเมนทางวัฒนธรรมต่างๆ”
ในขณะที่องค์กรต่างๆ จำนวนมากพยายามต่อสู้กับอคติและความลำเอียง พวกเขากลับถูกปล่อยให้แบกรับภาระหน้าที่นี้ในขณะที่รัฐบาลและบริษัทต่างๆ ที่ดูแลแพลตฟอร์มและเว็บไซต์ต่างๆ นิ่งเฉยอยู่เฉยๆ “กลุ่มบุคคลอิสระที่ใส่ใจในเรื่องนี้และเต็มใจที่จะใช้เวลาว่างไปกับเรื่องนี้ มีทรัพยากรและทักษะที่สูงกว่าสถาบันที่รับผิดชอบอย่างเป็นทางการ” แจ็กสันกล่าว
——————————————
แล้วคุณล่ะ? พร้อมจะเป็นส่วนหนึ่งในการรักษาประวัติศาสตร์ดิจิทัลของเราแล้วหรือยัง?
แหล่งอ้างอิง

